Qu'est-ce qu'une entreprise IA native ?
Les gains de l'IA atteignent 20 % pour un individu, mais 2 % à l'échelle de l'entreprise. Pourquoi cet écart, et à quoi ressemble concrètement une entreprise organisée autour de l'IA, avec deux agents qui tournent en production.
Colin Dargent & Achille Morin-Lemoine
Mis à jour le
Le replay
Vous utilisez ChatGPT ou Claude tous les jours. Vous allez plus vite. Pourtant, à l’échelle de votre entreprise, rien ne semble vraiment changer.
Ce n’est pas une impression. Les gains de productivité liés à l’IA tournent autour de 20 % au niveau d’un individu, mais retombent à 2 % au niveau des entreprises. Un facteur 10.
Ce guide reprend le contenu de notre premier webinaire. Il part de cet écart, l’explique, et montre à quoi ressemble concrètement une entreprise organisée autour de l’IA. Pas une théorie : ce que nous avons construit chez nous, avec deux agents qui tournent en production. Une précision d’entrée de jeu : on est aux prémices. On explore, on construit pour nos clients et pour nous. On ne vend pas une recette définitive, on partage ce qu’on voit sur le terrain, après deux ans et plus de 60 projets d’implémentation chez une quarantaine de clients.
L’IA rend les individus productifs, pas (encore) les entreprises
Le gain individuel est réel. Mais entre l’individu et l’entreprise, il y a une couche qui l’absorbe : la communication, la gestion de projet, l’alignement des équipes. Toutes ces frictions mangent le gain avant qu’il n’atteigne l’organisation.
L’automobile raconte la même histoire. Quand elle est arrivée, il a fallu une vingtaine d’années pour réorganiser le travail autour des chaînes de production. La technologie était là bien avant les gains. Ce qui manquait, c’était la réorganisation.
On vit exactement ça aujourd’hui. La plupart des entreprises ajoutent de l’IA par-dessus une organisation pensée pour des humains. Pour débloquer le niveau supérieur, il ne s’agit pas d’ajouter un outil de plus. Il s’agit de réorganiser le travail autour de l’IA.
Une entreprise IA native s’organise autour de sa donnée
S’il y a une seule chose à retenir : le cœur d’une entreprise IA native, c’est sa donnée centralisée.
La logique est simple. L’intelligence artificielle, c’est de l’intelligence. Une intelligence prend des décisions à partir de données. Donc une entreprise pensée pour l’IA doit d’abord rendre sa donnée accessible à l’IA, à un endroit où elle peut aller la chercher facilement.
Or aujourd’hui, votre donnée vit à deux endroits : dans des outils en silos, et dans la tête des gens. C’est ce qui la rend inexploitable automatiquement.
Concrètement, cette donnée centralisée tient en deux parties. D’un côté la donnée contextuelle : tout le qualitatif, vos notes, le contexte d’un client, vos façons de faire, vos décisions, stocké dans des fichiers texte lisibles par les humains comme par les agents (ce qu’on appelle un second cerveau). De l’autre la donnée quantitative : tout le structuré, vos leads, vos interactions, vos métriques, vos factures, rangé dans une base de données qu’un agent peut interroger.
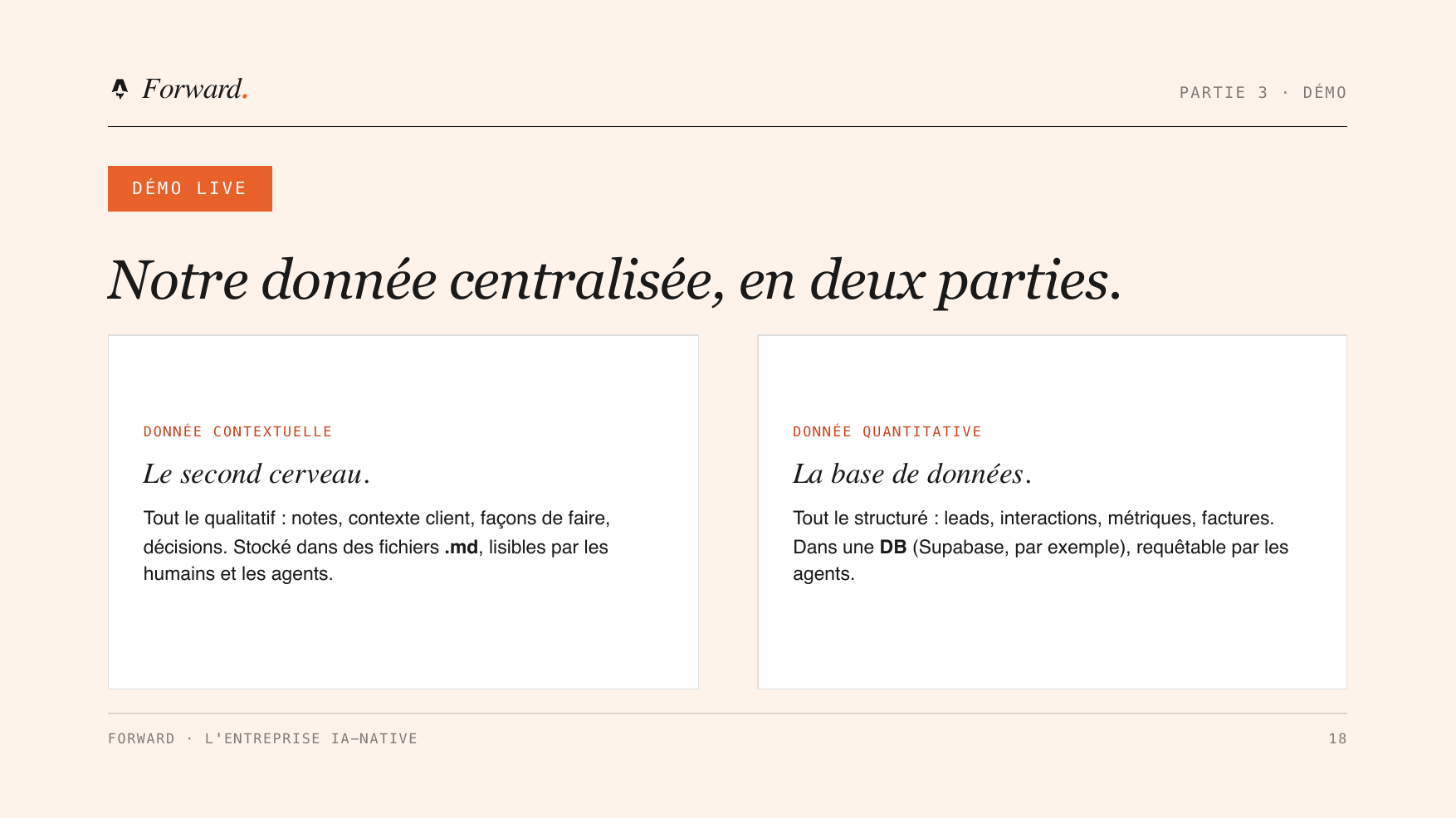
Sur le terrain, après deux ans à construire des automatisations, on observe la même constante : 60 à 70 % du travail consiste juste à aller chercher la donnée au bon endroit, dans un Google Sheet, un CRM, un canal Slack. Une fois la donnée centralisée, déployer un nouveau cas d’usage ne demande plus « qu’à » poser un prompt. On fait le travail de fond une fois, on construit dessus.
Deux choses ont changé récemment. Centraliser la donnée est devenu beaucoup plus rapide grâce à l’IA. Et une fois centralisée, elle s’exploite sans data analyst. Pour la première fois, c’est accessible à une PME, pas seulement à un grand groupe. (On détaille ce socle dans notre article sur la couche data commune pour agents IA.)
Le vrai problème : votre donnée est en silos
Prenez un seul client. Il existe dans votre outil de facturation, dans votre CRM, dans votre outil de gestion de projet, peut-être dans votre support. Quatre ou cinq fragments du même client, sans lien entre eux.
Pour répondre à une question simple comme « où en est-on avec ce client ? », une IA doit alors fouiller chaque outil, faire des recoupements, multiplier les appels. C’est lent, c’est cher, et souvent ça échoue.
Un exemple concret, tiré de notre propre base. À la question « quelles ont été les dernières interactions avec ce client ? », la réponse réunit 3 emails, 1 réunion, 2 factures et 3 échanges WhatsApp. Éparpillée dans quatre outils, cette synthèse prenait 20 minutes et mobilisait 2 personnes. Avec la donnée reliée : 10 secondes.

S’ajoute la donnée informelle : comment vous contactez tel client, sur quel ton vous lui parlez, ce qui a été décidé dans un appel. Cette intelligence-là ne vit nulle part ailleurs que dans une tête.
Ce que la donnée centralisée débloque
Une fois la donnée réunie, trois usages s’ouvrent, du plus simple au plus avancé.
- Décider. « Quel est mon client le plus rentable ? » devient une question à laquelle on répond en croisant facturation, temps passé et contexte, sans data scientist. Hier, ça demandait une vraie infrastructure. Aujourd’hui, c’est fait pour vous.
- Piloter les projets. Plus besoin de faire le tour des équipes pour savoir où on en est. Une minute après la fin d’une réunion, son transcript peut arriver automatiquement en base. Un agent répond ensuite à « où on en est sur ce projet ? » à votre place.
- Brancher des agents autonomes. Un agent qui doit piocher dans plusieurs outils en silo est moins efficace et plus cher en tokens. La donnée centralisée est la condition pour qu’il fonctionne bien.
On ne centralise pas tout d’un coup : cas d’usage par cas d’usage
C’est l’erreur classique : vouloir tout centraliser d’un seul mouvement. Impossible, et inutile.
La bonne approche tient en quatre temps :
- Identifier le cas d’usage qui a le plus de valeur pour vous.
- Centraliser uniquement la donnée nécessaire à celui-là.
- Poser dès le premier jour une architecture qui pourra accueillir le reste (scalable).
- Ajouter des briques au fur et à mesure des cas d’usage suivants.
Plus la base grandit, plus les cas d’usage suivants sont rapides à déployer. Certains ne se débloquent qu’une fois 100 % de la donnée centralisée : on y va par paliers, sans bloquer la valeur en attendant. C’est exactement la séquence qu’on applique pour centraliser la donnée avant de brancher les agents.
Pas sûr du premier cas d’usage à prioriser ?
C’est souvent le vrai point de blocage. En 30 minutes, on identifie ensemble le cas d’usage qui a le plus de valeur chez vous et la donnée à centraliser en premier.
Découvrir comment mon entreprise peut devenir IA native →« Agent » veut dire trois choses différentes
Le mot « agent » recouvre trois réalités qu’on confond souvent. Les distinguer évite beaucoup de malentendus.
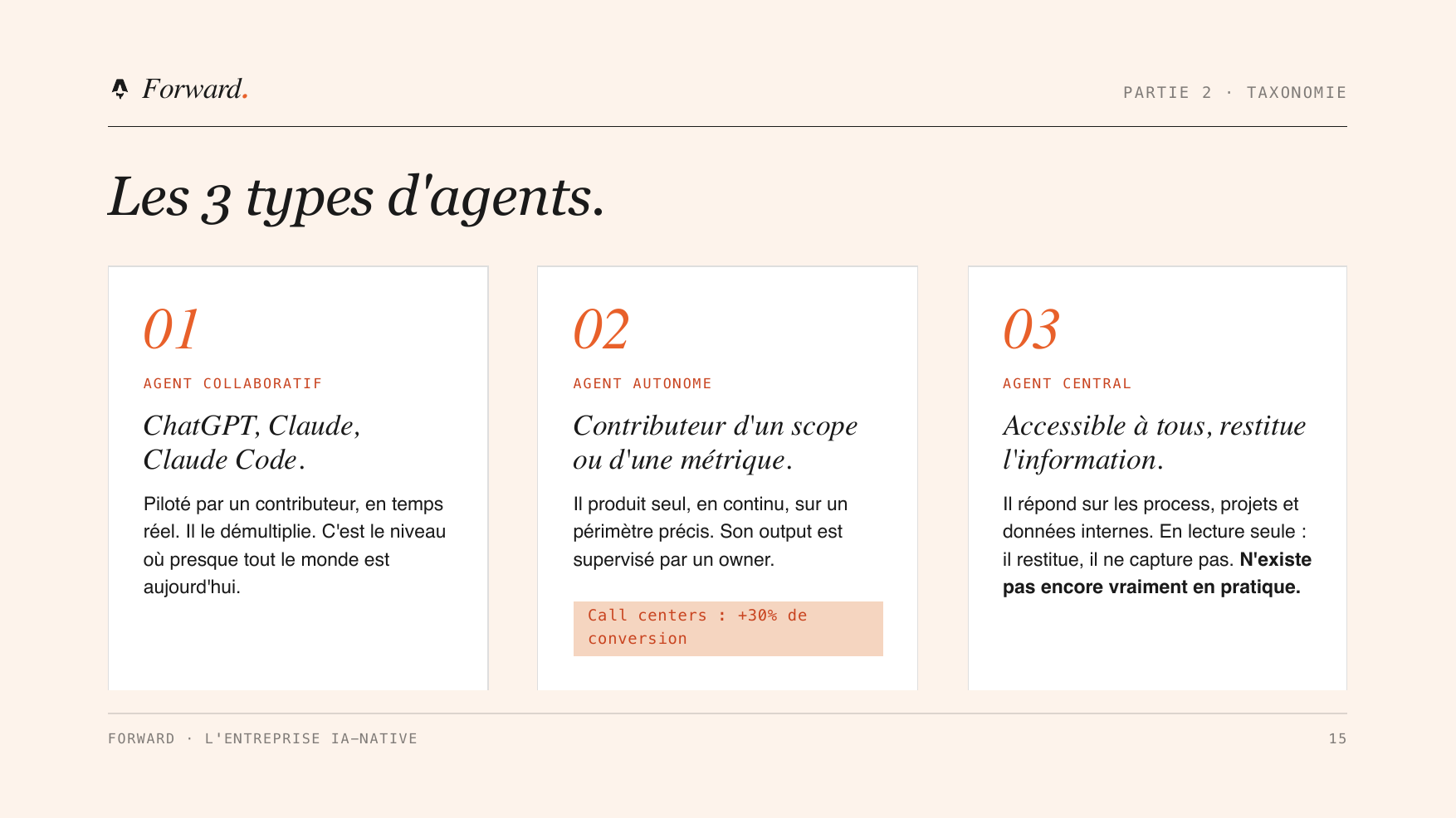
- L’agent collaboratif. C’est l’assistant que vous connaissez : ChatGPT, Claude, Claude Code. Vous le pilotez en direct, en tête-à-tête, pour accomplir des tâches. C’est là qu’en sont 90 % des gens aujourd’hui.
- L’agent autonome. Il est responsable d’un périmètre précis ou d’une métrique, et produit des résultats en continu, sous la supervision d’un humain. Exemple concret vu chez un client : un agent qui fait évoluer le script d’un call center semaine après semaine, mesure l’effet sur le taux de conversion, et ajuste. Résultat : +30 % de conversion.
- L’agent central. Accessible à toute l’équipe, il répond aux questions sur les process, les projets et les données internes. C’est la même interface pour tout le monde. En pratique, il n’existe pas encore vraiment.
Extrait du webinaire : les trois types d’agents, expliqués.
Une règle structure tout ça : un agent autonome a un seul propriétaire humain. Comme un collaborateur avec deux managers, un agent à l’ownership partagé crée de la confusion sur la responsabilité. Si un agent envoie un mauvais message ou touche au code en production, c’est un humain qui en répond. À l’inverse, une même personne peut piloter plusieurs agents. (Sur le bon niveau d’autonomie à confier, voir calibrer l’autonomie d’un agent.)

À quoi ressemble l’organisation
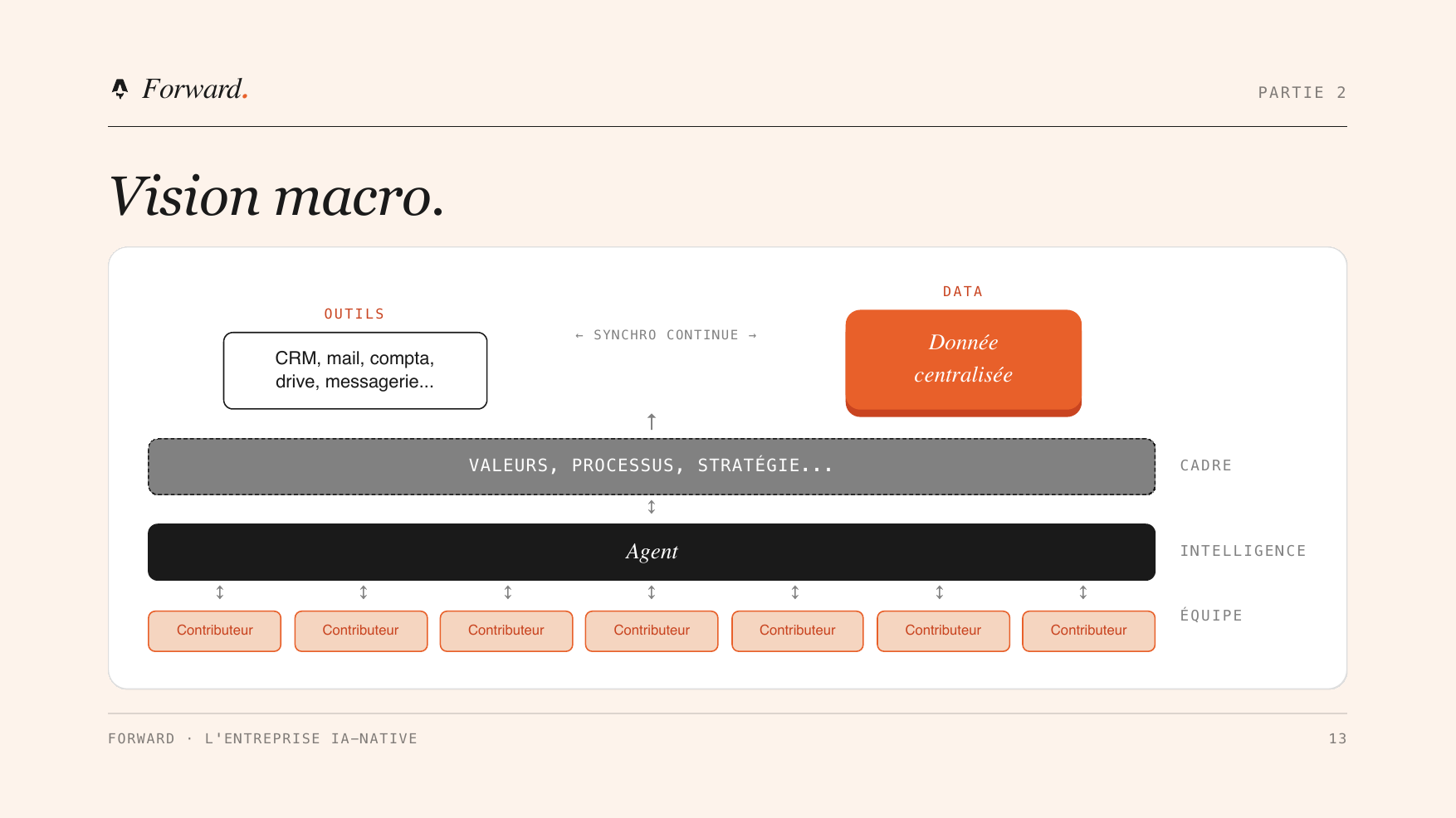
La carte d’une entreprise IA native tient en quelques couches :
- Au centre, la donnée centralisée. Le cerveau, alimenté en continu par une synchro avec vos outils.
- Une couche de connaissance. Vos valeurs, vos process, vos décisions, mis à plat pour être lisibles par une IA.
- Une couche d’agents. Collaboratifs, autonomes, central : ils interagissent avec la donnée et avec les outils pour produire le travail.
- Des humains responsables. Chaque métrique a un propriétaire humain, qui s’appuie sur des contributeurs, humains ou agents. Ce qui compte, c’est que le travail soit fait, peu importe par qui.
La preuve : deux agents qui tournent chez nous
On n’a pas tout centralisé. On a fait l’inverse de ce qu’on déconseille de faire : on a pris un objectif (créer deux agents), centralisé la donnée utile à ces deux-là, avec une architecture directement extensible. Voici le résultat.
Manu, l’agent contenu
Manu rédige et publie des articles sur notre site, seul, sans qu’on lui donne d’instruction. Notre pari : augmenter la valeur vie de notre audience sans prendre plus de clients.
Son parcours : il parcourt notre second cerveau (des fichiers texte synchronisés sur GitHub), en tire deux ou trois thématiques, fait une analyse SEO pour choisir la plus prometteuse, vérifie qu’il n’y a pas de redondance avec l’existant, rédige l’article avec le maillage interne, le publie, et enregistre tout dans la base centrale.

Coût moyen : 2 à 3 $ par article, tokens et crédits compris.
La vraie différence avec un simple assistant : Manu est branché aux statistiques de trafic du site. Chaque semaine, il peut regarder si ses articles ont généré des visites et ajuster les suivants. C’est ce qu’on appelle une boucle fermée : il prend du recul sur ses propres résultats et s’améliore.
Démo en direct : Manu, de la source à l’article publié.
Melvin, l’agent acquisition
Melvin transforme un signal LinkedIn en conversation qualifiée, de bout en bout, avec une validation humaine au moment clé.
En amont, chaque jour, les gens qui réagissent à nos posts sont enregistrés dans la base. Un premier filtre déterministe (un mélange de script et d’appels IA, pour économiser les tokens) ne garde que les profils pertinents : fondateurs de PME en France, bonne taille, bon secteur.
Ensuite, Melvin fait ses devoirs sur chaque lead retenu : il scrape le site, cherche une actualité (une levée, un projet de modernisation), évalue le potentiel de transformation IA de l’entreprise. Puis il tranche, rédige un brouillon de message personnalisé dans notre ton, et le poste dans Slack avec sa recommandation : contacter, douter, ou ignorer.
On répond alors en un mot : envoie, modifie, ou skip. Melvin exécute, met à jour la base, relance automatiquement à J+3 avec le dernier article de Manu, et nous envoie un récap chaque semaine.

Sur deux semaines : 51 leads analysés, 26 recommandés au contact, 16 messages envoyés, 14 relances, 2 réponses. On est encore en phase de réglage. C’est normal : un agent, comme un nouveau collaborateur, a besoin d’une période de formation avant de gagner en autonomie.
Le point important n’est pas le score à date, c’est l’architecture : chaque étape, pour Manu comme pour Melvin, lit et écrit dans la même donnée centralisée. C’est la thèse du webinaire, en action.
Démo en direct : Melvin, d’un signal LinkedIn à une conversation qualifiée.
Vous voulez les mêmes agents chez vous ?
Manu et Melvin ne sont pas des prototypes : ils tournent en production sur notre donnée centralisée. On peut construire le vôtre, branché sur votre métier et votre donnée.
Découvrir comment mon entreprise peut devenir IA native →Les trois pièges à anticiper
Rien de magique là-dedans. Trois points de vigilance reviennent à chaque déploiement.
- La gouvernance. Qui accède à quelle donnée, agents comme humains. Vous ne voulez pas qu’un agent central donne les dossiers RH ou les chiffres financiers à n’importe qui. Ça se gère très bien, mais ça se pense en amont.
- Les coûts. Construire sur un abonnement type Claude Code (20 à 90 €/mois) est subventionné et largement suffisant. Dès qu’on passe en API directe, le token coûte beaucoup plus cher. Le bon réflexe : voir le coût de l’IA comme un pourcentage du coût salarial, dans une fourchette raisonnable de 3 à 10 % par an.
- La traçabilité. Chaque action d’un agent doit être auditable via des logs. Ça existe depuis toujours en informatique, mais l’AI Act en fait progressivement une obligation en Europe. Ce n’est pas le far west : on garde des traces.
On est aux prémices. C’est maintenant que ça se joue.
Centraliser sa donnée est un chantier. Il se mène sur plusieurs mois, et il n’est jamais vraiment « fini » : il faut ensuite maintenir la donnée et les workflows. Mais on le mène par étapes, cas d’usage par cas d’usage, en gardant en tête l’objectif de long terme. Chaque brique s’emboîte dans la suivante : c’est une logique de construction, pas une succession de coups isolés.
Cette transformation prendra des années. Dans dix ans, il y aura encore des entreprises qui n’auront pas pris le virage. Commencer aujourd’hui, même petit, c’est prendre des années d’avance.
La présentation du webinaire
Vous préférez les slides ? La présentation complète qui a servi de support au webinaire est disponible en téléchargement.
Télécharger la présentation (PDF)
Envie de voir ce que ça donnerait chez vous ?
On regarde votre cas concret en 30 minutes : par où commencer, quel premier cas d’usage, ce que ça peut débloquer. Deux praticiens IA-natifs, deux ans et plus de 60 projets d’implémentation derrière nous. Sans engagement.
Découvrir comment mon entreprise peut devenir IA native →FAQ
Faut-il vraiment tout centraliser dans une base de données ?
Non. On commence par centraliser les identifiants d’une même entité éparpillée dans plusieurs outils (un client présent dans la facturation, le CRM, la gestion de projet), pas 100 % des données. Les outils gardent leur rôle : pour facturer, il faut toujours un outil de facturation. On rapatrie en plus seulement les données qu’aucun outil ne capte (par exemple les réactions à vos posts LinkedIn).
Comment relier un même client présent dans plusieurs outils ?
Par les identifiants. Chaque outil attribue un ID à une personne. On stocke dans la base centrale la correspondance entre ces ID pour une même personne. Quand on interroge l’IA, elle trouve d’abord tous les ID liés au client au même endroit, puis navigue dans les outils sans multiplier les recherches : c’est plus rapide et moins cher en tokens.
Peut-on récupérer automatiquement les appels téléphoniques ?
Oui. Avec un outil d’enregistrement comme Allo, Ringover ou Aircall, le transcript de l’appel part automatiquement dans votre base, relié au bon contact via son identifiant ou son numéro. Si le numéro ne correspond à personne, l’agent vous notifie pour que vous identifiiez la personne une fois, et l’information est enregistrée pour toujours.
Est-ce compatible avec la souveraineté des données et la conformité ?
Oui. En hébergeant la base sur une solution européenne et en passant par un routeur de modèles comme OpenRouter avec Mistral (ou un modèle que vous faites tourner vous-même), la donnée ne quitte jamais votre infrastructure. Le framework des agents est indépendant du fournisseur de modèle : vous gardez les capacités agentiques sans dépendance.
Combien coûte un agent autonome, et comment juger si ça vaut le coup ?
On le juge comme une ressource : au coût par résultat produit. Un article qui coûte 2 à 3 $ et génère du trafic, c’est une ressource qu’on choisit d’investir ; à 10 $ l’article, ce ne serait pas viable. Pour construire, un abonnement type Claude Code ou Codex (20 à 90 €/mois) revient beaucoup moins cher que l’appel direct à l’API.
Vous voulez avancer ?
On construit les systèmes IA
que vos équipes pilotent.
Deux praticiens IA-natifs. Des résultats tangibles, chaque semaine.